Here is a post to demonstrate the installation process of the latest release of SQL Server, DENALI CTP3 (not CTP1).
Steps:
1. Run the SETUP executable to start the installation wizard.

2. Installation Center appears with lot of options. We are looking for installation, so click it.

3. Specify the Installation type; a fresh installation or a add features to existing installation.

4. A fresh installation looking forward to install all the components of CTP3.

5. Select All Components.

6. Installation Rules passed, so route clear for the next steps.

7. Wanna make it a Default instance or a Named instance?
I named the instance as DENALICTP3. I already have the CTP1 with instance name DENALI.

8. Checks the Disk Space requirements. Everything is good here....

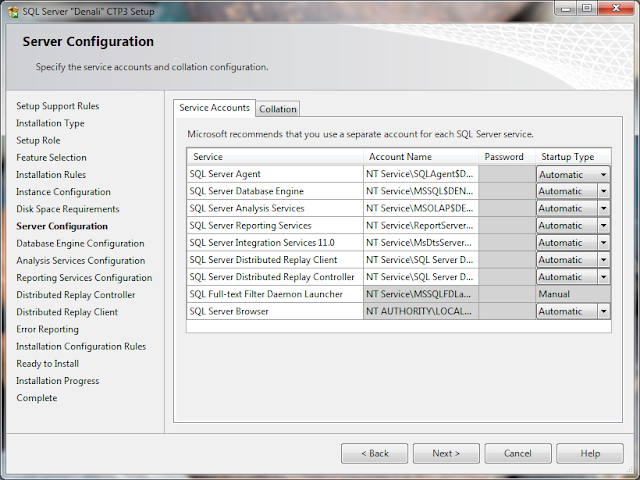
9. Configuring the Service Accounts and Service Startup Types. I went with the default collation here.
10. I have not set the Mixed mode authentication here, just went with the default windows authentication.
However, we can enable Mixed mode anytime after the instance is setup.

11. One can change the location of the directories from default C:\Program Files\Microsoft SQL Server\ to any other drive.....

12. Analysis Services Configuration page set to Multidimensional and Data Mining Mode.

13. Reporting Services Install and Configure with Native Mode.

14. Sam has given the permissions for the Distributed Replay Controller service.

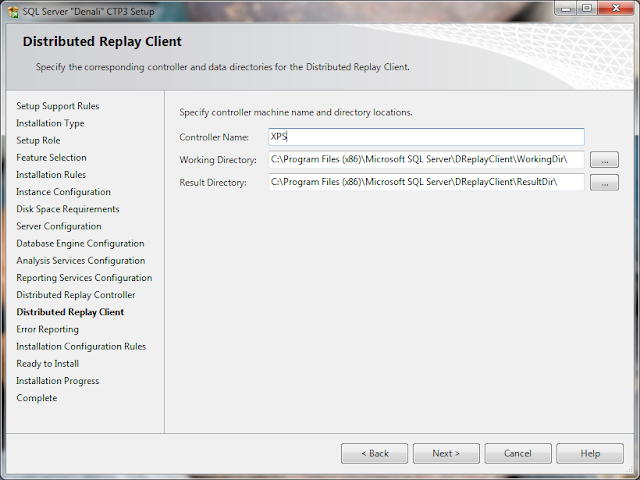
15. Specify a controller machine name and folder locations for Distributed Replay Client.
16. Reports errors automatically to Microsoft, if faces any.

17.Verifies the configuration rules.

18. Ready to start.....

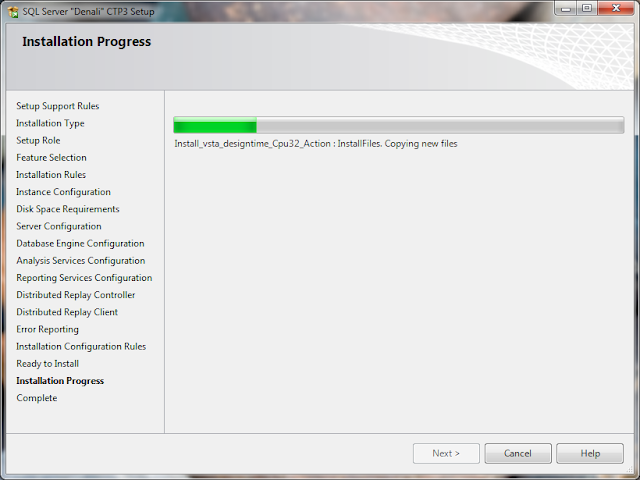
19. Installation in progress......


20. Success!!! The installation of SQL Server "DENALI" CTP3 is a succeeded.


22. Check the services of various SQL Server Components including DB Engine, IS, AS, RS, Agent, DR Controller and Client etc.,

And whats the next step, simply start exploring.....good luck........!! :)
Steps:
1. Run the SETUP executable to start the installation wizard.

2. Installation Center appears with lot of options. We are looking for installation, so click it.

3. Specify the Installation type; a fresh installation or a add features to existing installation.

4. A fresh installation looking forward to install all the components of CTP3.

5. Select All Components.

6. Installation Rules passed, so route clear for the next steps.

7. Wanna make it a Default instance or a Named instance?
I named the instance as DENALICTP3. I already have the CTP1 with instance name DENALI.

8. Checks the Disk Space requirements. Everything is good here....

9. Configuring the Service Accounts and Service Startup Types. I went with the default collation here.

10. I have not set the Mixed mode authentication here, just went with the default windows authentication.
However, we can enable Mixed mode anytime after the instance is setup.

11. One can change the location of the directories from default C:\Program Files\Microsoft SQL Server\ to any other drive.....

12. Analysis Services Configuration page set to Multidimensional and Data Mining Mode.

13. Reporting Services Install and Configure with Native Mode.

14. Sam has given the permissions for the Distributed Replay Controller service.

15. Specify a controller machine name and folder locations for Distributed Replay Client.

16. Reports errors automatically to Microsoft, if faces any.

17.Verifies the configuration rules.

18. Ready to start.....

19. Installation in progress......



20. Success!!! The installation of SQL Server "DENALI" CTP3 is a succeeded.

21. Restart the machine to complete the installation process totally.

22. Check the services of various SQL Server Components including DB Engine, IS, AS, RS, Agent, DR Controller and Client etc.,

And whats the next step, simply start exploring.....good luck........!! :)











